外观
Django框架-增强博客并添加社交功能
上一节课我们用视图、模板和 URL 开发了一个简单的博客应用,学习了 Django 的核心组件。这节课我们继续扩展这个博客应用,给它加上一些常见博客平台都有的功能。
本节将学习以下内容:
添加博文作者
使用规范 URL 管理模型
给博文列表添加分页功能
基于类的视图
通过表单给博文添加评论功能
注:上节课案例代码:mysite.zip
- 在正式学习之前请先下载上节课案例代码,接下来在此项目案例代码上继续编写。
一、增强博客的admin后台管理
1. 为博文添加作者(多对一关系)
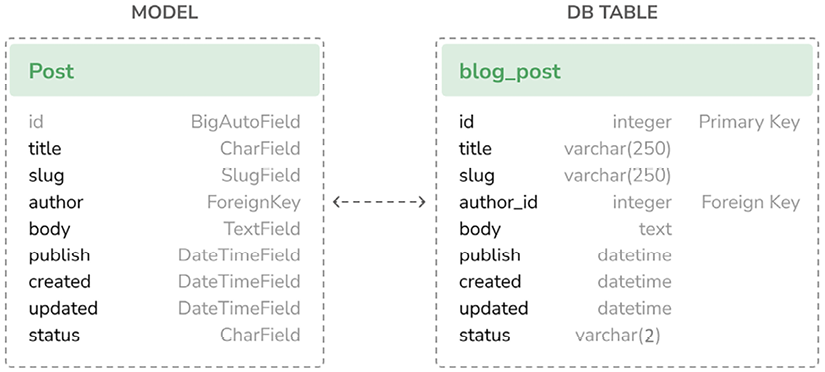
每篇博文都有一个作者,所以我们需要建立用户和博文之间的关联,记录每篇博文是谁写的。Django 自带了一套用户认证框架,包含在
<username>django.contrib.auth包中,里面有一个现成的User模型。要把用户和博文关联起来,我们用<username>AUTH_USER_MODEL这个配置项,它默认指向<username>即auth.User模型。通过这个配置,你也可以在项目中替换成自定义的用户模型。编辑应用程序
blog/models.py文件中的Post博文模型,使其内容如下所示。
...
from django.conf import settings # 访问Django设置
class Post(models.Model):
...
slug = models.SlugField(
'URL标识',
max_length=250,
unique_for_date='publish' # 同一发布日期的slug必须唯一
)
author = models.ForeignKey(
settings.AUTH_USER_MODEL, # 使用settings中配置的用户模型
on_delete=models.CASCADE, # 用户删除时删除其所有文章
related_name='blog_posts',#从User反向查询:user.blog_posts.all()
verbose_name='作者'
)
body = models.TextField('文章内容')
...- 完整的 Post 模型与数据库表对应关系
重力铁链与深渊
Gravity Chain & Abyss (ForeignKey CASCADE)
DATABASE DELETION ABYSS
USER: admin
Post: "My Django Setup"
Post: "Learn Views"
Post: "Hello World"
author = models.ForeignKey(User, on_delete=models.CASCADE)on_delete=models.CASCADE 是极具破坏性的级联删除。父对象 User 岩石一旦被摧毁,下方所有的从属 Post 岩石会被牵连切断锁链,坠入深渊全部销毁。
CASCADE is a destructive cascading deletion. Once the parent User rock is destroyed, all subordinate Post rocks attached via foreign keys fall into the database abyss.
2. 添加博客评论Comment模型:
- 在
blog/models.py文件中添加 Comment评论模型,具体代码如下:
... ...
# Comment 模型 - 博客评论
class Comment(models.Model):
post = models.ForeignKey(
Post,
on_delete=models.CASCADE,
related_name='comments', # 从Post反向查询:post.comments.all()
verbose_name='所属博文'
)
name = models.CharField('姓名', max_length=80)
email = models.EmailField('邮箱')
body = models.TextField('评论内容')
created = models.DateTimeField('创建时间', auto_now_add=True)
updated = models.DateTimeField('更新时间', auto_now=True)
active = models.BooleanField('是否激活', default=True)
# 自定义对应的表名,默认表名:blog_comment
class Meta:
verbose_name = '评论信息' # 在Admin中显示的单数形式名称
verbose_name_plural = '评论信息管理'# 在Admin中显示的复数形式名称
ordering = ['created'] # 默认按发布时间降序排列(最新的在前)
indexes = [
models.Index(fields=['created']), # 为created字段创建索引
]
# 返回对象的字符串表示
def __str__(self):
# 返回评论者姓名及对应文章标题
return f'评论人:{self.name} , 博文:{self.post}'接下来,我们把新的 Comment 模型注册到 admin 后台,方便通过管理界面来管理评论。
在 blog/admin.py 文件中导入 Comment 模型,具体admin.py的完整代码如下:
# 导入Django的admin模块
from django.contrib import admin
# 导入博客应用中的Comment和Post模型
from .models import Comment, Post
# 注册Post模型到Admin站点(装饰器写法)
@admin.register(Post)
class PostAdmin(admin.ModelAdmin):
# 在Admin中显示的字段
list_display = ['title', 'slug', 'author', 'publish', 'status']
# 过滤选项(侧边栏)
list_filter = ['status', 'created', 'publish', 'author']
search_fields = ['title', 'body'] # 搜索字段
prepopulated_fields = {'slug': ('title',)} # slug字段自动填充
raw_id_fields = ['author']
date_hierarchy = 'publish' # 日期分层导航
ordering = ['status', 'publish'] # 默认排序
show_facets = admin.ShowFacets.ALWAYS # 始终显示侧边栏过滤器
# 注册Comment模型到Admin站点(装饰器写法)
@admin.register(Comment)
class CommentAdmin(admin.ModelAdmin):
# 在Admin中显示的字段
list_display = ['name', 'email', 'post', 'created', 'active']
list_filter = ['active', 'created', 'updated'] # 过滤选项(侧边栏)
search_fields = ['name', 'email', 'body'] # 搜索字段
# 可选:自定义 Admin 站点标题
admin.site.site_header = '博客管理系统' # 登录页面和后台顶部标题
admin.site.site_title = '博客管理后台' # 浏览器标签页标题
admin.site.index_title = '欢迎使用博客管理系统' # 首页标题- 完整 blog/models.py 博客的模型文件代码如下:
from django.conf import settings # 访问Django设置
from django.db import models # Django的ORM模型
from django.urls import reverse # URL反向解析
from django.utils import timezone # Django时区工具
# 自定义模型管理器,用于过滤已发布的文章,继承自 models.Manager
class PublishedManager(models.Manager):
# 重写 get_queryset() 方法
def get_queryset(self):
# 获取所有已发布文章,并返回
return (
super().get_queryset().filter(status=Post.Status.PUBLISHED)
)
# Post 模型 - 博客文章
class Post(models.Model):
class Status(models.TextChoices): # 状态选择类
DRAFT = 'DF', '草稿'
PUBLISHED = 'PB', '已发布'
title = models.CharField('文章标题',max_length=250)
# SlugField 是 Django 中的一个特殊字符字段,专门用于存储 URL 友好的字符串。
# slug 是URL友好的版本,如 "my-blog-post-2023"
slug = models.SlugField(
'URL标识',
max_length=250,
unique_for_date='publish' # 同一发布日期的slug必须唯一
)
author = models.ForeignKey(
settings.AUTH_USER_MODEL, # 使用settings中配置的用户模型
on_delete=models.CASCADE, # 用户删除时删除其所有文章
related_name='blog_posts', #从User反向查询user.blog_posts.all()
verbose_name='作者'
)
body = models.TextField('文章内容') # 文章正文
publish = models.DateTimeField('发布时间',default=timezone.now)
created = models.DateTimeField('创建时间',auto_now_add=True)
updated = models.DateTimeField('更新时间',auto_now=True)
status = models.CharField(
'文章状态',
max_length=2,
choices=Status, # 使用上面自定义的Status类选择项
default=Status.DRAFT # 默认状态为草稿
)
objects = models.Manager() # 默认管理器,保持所有查询
published = PublishedManager() # 自定义管理器,只返回已发布文章
# 自定义对应的表名,默认表名:blog_post
class Meta:
db_table="blog_post" # 自定义表名(默认就是这个可省略)
verbose_name = '博文信息' # 在Admin中显示的单数形式名称
verbose_name_plural = '博文信息管理'# 在Admin中显示的复数形式名称
ordering = ['-publish'] # 默认按发布时间降序排列(最新的在前)
indexes = [ # 为publish字段创建索引
models.Index(fields=['-publish']),
]
# 返回对象的字符串表示
def __str__(self):
return self.title
# 模型方法:获取文章的绝对URL
def get_absolute_url(self):
return reverse(
'blog:post_detail', # URL命名空间:blog,名称为post_detail
args=[
self.id,
# self.publish.year,
# self.publish.month,
# self.publish.day,
# self.slug, # 生成类似 /2023/10/15/my-blog-post/ 的URL
],
)
# Comment 模型 - 博客评论
class Comment(models.Model):
post = models.ForeignKey(
Post,
on_delete=models.CASCADE,
related_name='comments', # 从Post反向查询:post.comments.all()
verbose_name='所属博文'
)
name = models.CharField('姓名', max_length=80)
email = models.EmailField('邮箱')
body = models.TextField('评论内容')
created = models.DateTimeField('创建时间', auto_now_add=True)
updated = models.DateTimeField('更新时间', auto_now=True)
active = models.BooleanField('是否激活', default=True)
# 自定义对应的表名,默认表名:blog_comment
class Meta:
verbose_name = '评论信息' # 在Admin中显示的单数形式名称
verbose_name_plural = '评论信息管理'# 在Admin中显示的复数形式名称
ordering = ['created'] # 默认按发布时间降序排列(最新的在前)
indexes = [
models.Index(fields=['created']), # 为created字段创建索引
]
# 返回对象的字符串表示
def __str__(self):
# 返回评论者姓名及对应文章标题
return f'评论人:{self.name} , 博文:{self.post}'沙漏与有色滤网
Sandglass Filters (Custom Manager `published` vs `objects`)
DATABASE (All Posts)
filter(status='PB')
PB
PB
PB
DF
DF
DF
objects 像一个直筒管子,所有已发布和草稿数据都会倾泻而下;而自定义的 published 管理器则在管道中永久插入了一张滤网 filter(status='PB'),所有标着 DF(Draft) 的草稿数据将直接被拦截筛选出去。
The default `objects` manager lets all data pour through. The custom `published` manager inserts a permanent filter that intercepts and blocks all Draft posts, letting only Published ones pass.
3. 重置博客数据库
注意:由于上面操作修改了 Post模型结构,需要重新
(1). 清空历史数据
删除 blog/migrations/目录下的迁移文件
删除项目下的 db.sqlite3 数据文件
(2). 数据迁移
- 创建迁移文件,在blog/migrations/目录下:
$ python manage.py makemigrations blog- 运行以下命令实现网站Admin管理的数据结构迁移:
$ python manage.py migrate- 也可执行下面命令来查看数据结构迁移后的效果。
$ python manage.py showmigrations(3). 创建管理员用户
首先,我们需要创建一个可以登录管理后台的用户。运行以下命令:
$ python manage.py createsuperuser
# 输入您所需的用户名,然后按Enter键。
Username: admin
# 然后将提示您输入所需的电子邮件地址:
Email address: admin@example.com
# 最后一步是输入你的密码(>=8位)。您将被要求输入密码两次,第二次作为第一次的确认
Password: **********
Password (again): *********
Superuser created successfully.(4). 启动开发服务器
Django 的管理后台默认就是开启的,下面我们启动开发服务器来看看效果。
启动开发服务器命令如下:
$ python manage.py runserver
或
$ python manage.py runserver 0.0.0.0:8000(5). 浏览器预览效果
现在,打开一个Web浏览器,访问地址: http://127.0.0.1:8000/admin/
- admin后台管理登录界面

- 后台管理首页
- 添加博文界面
- 博文列表浏览
- 添加评论页面
- 浏览评论信息
二、使用规范 URL 管理模型
注:上面已给出 blog/model.py 文件中的完整代码,下面介绍模型不用做实际操作。
1. 使用reverse函数解析URL
一个网站可能有多个页面显示相同的内容。规范 URL(Canonical URL)就是某个资源的"首选地址",可以理解为这个内容最正式、最具代表性的链接。虽然你的网站上可能有多个页面都能看到某篇博文,但每篇博文应该有一个固定的主 URL。
Django 允许你在模型中定义
get_absolute_url()方法,用来返回这个模型对象的规范 URL。Django 提供了多种 URL 解析函数,可以根据 URL 名称和参数动态生成 URL。这里我们用
django.urls模块中的reverse()函数。编辑blog应用中
blog/models.py文件,导入reverse()函数,并在Post模型中添加get_absolute_url()方法,具体如下所示。
... ...
from django.urls import reverse # URL反向解析
... ...
# Post 模型 - 博客文章
class Post(models.Model):
... ...
# 模型方法:获取文章的绝对URL
def get_absolute_url(self):
return reverse(
'blog:post_detail', # URL命名空间:blog,名称为post_detail
args=[self.id],
)
... ...- 在 blog/templates/blog/post/list.html 模板文件中使用上面定义的获取URL函数。
<a href="{% url 'blog:post_detail' post.id %}">
{{ post.title }}
</a>
改成如下:
<a href="{{ post.get_absolute_url }}">
{{ post.title }}
</a>总机反向寻址
Switchboard Reverse Lookup (`get_absolute_url` & `reverse`)
Operator Board
reverse( 'blog:post_detail', args=[1] )
URL Dispatcher Matrix
/
Namespace: 'blog'
-> /blog/
-> /blog/
name='post_list'
-> ''
-> ''
name='post_detail'
-> '<int:id>/'
-> '<int:id>/'
_
不建议在代码或模板中硬编码 URL!通过 `reverse` 函数提供名字和参数,Django 如同总机接线员般,瞬间向路由表发光回溯,物理拼接并返回对应的绝对网址。
Do not hardcode URLs! By passing the view name and arguments to `reverse`, Django acts like a switchboard operator, dynamically tracing the URL dispatcher to return the correct absolute path.
2. 创建对搜索引擎友好的URL(了解)
目前博文详情页的 URL 是
/blog/1/这种形式。下面我们来优化它,创建对搜索引擎更友好的 URL。我们用博文的发布日期(publish)和别名(slug)来拼接 URL,最终效果类似这样:/blog/2024/1/1/who-was-django-reinhardt/。这样的 URL 既包含标题又包含日期,更方便搜索引擎索引。为了能根据发布日期和别名(slug)的组合来精确查找某篇博文,我们需要确保同一天不会出现两篇 slug 相同的博文。我们通过给
slug字段加上按日期唯一的约束来实现这一点。编辑
blog/models.py文件,给Post模型的slug字段添加unique_for_date参数:
... ...
# SlugField 是 Django 中的一个特殊字符字段,专门用于存储 URL 友好的字符串。
# slug 是URL友好的版本,如 "my-blog-post-2023"
slug = models.SlugField(
'URL标识',
max_length=250,
unique_for_date='publish' # 同一发布日期的slug必须唯一
)
... ...
# 模型方法:获取文章的绝对URL
def get_absolute_url(self):
return reverse(
'blog:post_detail', # URL命名空间:blog,名称为post_detail
args=[
self.publish.year,
self.publish.month,
self.publish.day,
self.slug, # 生成类似 /2023/10/15/my-blog-post/ 的URL
],
)- 编辑
blog/urls.py自定义URL路由配置文件,具体如下所示:
from django.urls import path
from . import views
app_name = 'blog'
urlpatterns = [
# Post views
path('', views.post_list, name='post_list'), # 博文列表路由
# 下面两个不同的博文详情路由
path('<int:id>/', views.post_detail, name='post_detail'),
path(
'<int:year>/<int:month>/<int:day>/<slug:post>/',
views.post_detail,
name='post_detail2',
),
]- 编辑 blog/views.py 视图文件:
... ...
# 博客文章详情视图,显示单篇文章及其评论
def post_detail(request, year, month, day, post):
# def post_detail(request, id):
# 使用get_object_or_404函数简化查询和异常处理
post = get_object_or_404(
Post, # 要查询的模型类
status=Post.Status.PUBLISHED, # 只查询已发布的文章
# id=id, # 根据传入的id参数进行查询
slug=post,
publish__year=year,
publish__month=month,
publish__day=day,
)
# List of active comments for this post
comments = post.comments.filter(active=True)
# Form for users to comment
form = CommentForm()
return render(
request,
'blog/post/detail.html',
{
'post': post,
'comments': comments,
'form': form
},
)
... ...四级拨盘与路由全映射
Combination Decoding (SEO-Friendly URL Params)
URL Dispatcher Combination Lock
domain.com/blog/
2026
<int:year>
/
03
<int:month>
/
24
<int:day>
/
django-intro
<slug:post>
/
def post_detail(request, year=2026, month=3, day=24, post='django-intro'):
post = get_object_or_404(Post,
publish__year=2026,
publish__month=3,
publish__day=24,
slug='django-intro'
)
包含多重路径转换器的 SEO URL 就像一个四级并发密码锁。每当你拨动浏览器地址栏中的年月或字串时,如同齿轮精准咬合,底层 Python 视图函数的对应形参也会瞬间锁定并捕获这些值用于数据查询。
An SEO URL with multiple converters acts like a combination lock. Rolling the values in the URL instantly mechanically locks the corresponding parameter values in the underlying Python view function.
注意:若是修改了models.py
三、添加分页
1. 给博文列表添加分页功能
我们来给博文列表加上分页功能,这样用户就可以方便地翻页浏览所有博文了。
编辑
blog/views.py视图文件,导入 Django 内置的Paginator分页类,具体如下
# Paginator: 用于分页显示查询结果
# PageNotAnInteger: 处理页码不是整数的异常
# EmptyPage: 处理页码超出范围的异常
from django.core.paginator import EmptyPage, PageNotAnInteger, Paginator
# get_object_or_404: 如果查询对象不存在,自动返回404页面,简化异常处理
# render: 将模板和上下文数据渲染为HTTP响应,是常用的视图函数
from django.shortcuts import get_object_or_404, render
from .models import Post # 导入Post模型
# 博客文章列表视图,支持分页
def post_list(request):
post_list = Post.published.all() # 获取所有已发布文章
paginator = Paginator(post_list, 3) # 每页显示3篇文章
page_number = request.GET.get('page', 1) # 获取当前页码,默认第一页
try:
# 获取当前页的文章列表,如果页码无效会抛出异常
posts = paginator.page(page_number)
except PageNotAnInteger:
# 处理页码不是整数的情况,返回第一页
posts = paginator.page(1)
except EmptyPage:
# 处理页码超出范围的情况,返回最后一页
posts = paginator.page(paginator.num_pages)
return render(
request, # 请求对象,模板中可以使用请求上下文
'blog/post/list.html', # 模板路径(从templates目录开始)
{'posts': posts} # 上下文数据,将posts传递给模板
)
... ...下面来看看上面这段代码做了什么:
我们创建了一个
Paginator实例,设置每页显示 3 篇博文。我们从 GET 请求参数中获取
page的值,存到page_number变量里。如果请求中没有page参数,就默认显示第 1 页。调用
Paginator的page()方法,获取指定页码的数据。这个方法返回一个Page对象,我们把它存到posts变量中。最后把
posts对象传给模板进行渲染。
2. 创建分页模板
我们需要做一个翻页导航条,让用户可以在不同页面之间切换。我们把它写成一个通用模板,这样以后其他地方需要分页时也能直接复用。
在
templates/目录下新建一个pagination.html文件,添加以下 HTML 代码:
blog 应用目录
├── templates # 默认博客模版目录
│ ├── pagination.html # 通用模板分页导航模板
│ └── blog
│ ├── base.html # 公共博文父模版文件
│ └── post
│ ├─ list.html # 博文列表模版文件
│ └─ detail.html # 博文详情模版文件- 创建 blog/templates/pagination.html 分页导航文件,代码如下:
<div class="pagination">
<span class="step-links">
{% if page.has_previous %}
<a href="{% querystring page=page.previous_page_number %}">上一页</a>
{% endif %}
<span class="current">
当前第{{ page.number }}页,共计{{ page.paginator.num_pages }}页
</span>
{% if page.has_next %}
<a href="{% querystring page=page.next_page_number %}">下一页</a>
{% endif %}
</span>
</div>- 编辑 blog/templates/blog/post/list.html 模版文件,引入分页导航模板:
{% extends "blog/base.html" %}
{% block title %}程序员的小屋{% endblock %}
{% block content %}
<h1>程序员的小屋</h1>
{% for post in posts %}
<h2>
<a href="{{ post.get_absolute_url }}">
{{ post.title }}
</a>
</h2>
<p class="date">
发布时间: {{ post.publish }} 作者:{{ post.author }}
</p>
{{ post.body|truncatewords:30|linebreaks }}
{% endfor %}
{% include "pagination.html" with page=posts %}
{% endblock %}- 预览效果:

3. 基于类的视图
前面我们用的都是基于函数的视图(FBV)来写博客应用。函数视图简单直观,但 Django 同样支持用类来写视图。
和函数视图相比,基于类的视图(CBV)在某些场景下有明显优势。基于类的视图可以:
把不同 HTTP 方法(比如
GET、POST、PUT)的处理逻辑拆分到各自的方法中,不用写一堆 if-else 来判断。通过多重继承来创建可复用的视图组件(也叫 mixin)。
用基于类的视图展示博文列表
为了理解基于类的视图怎么写,我们来创建一个类视图,功能和之前的 post_list 函数视图一样。我们继承 Django 提供的 ListView 通用视图类,它专门用来展示对象列表。
编辑 blog/views.py 视图文件,添加以下代码:
... ...
# ListView: Django通用视图类,用于显示对象列表
from django.views.generic import ListView
... ...
# 备选博客文章列表视图类,使用Django通用视图ListView
class PostListView(ListView):
queryset = Post.published.all()
context_object_name = 'posts'
paginate_by = 3
template_name = 'blog/post/list.html'
... ...这个 PostListView 实现的功能和之前的 post_list 函数视图一样。我们定义了一个继承自 ListView 的类视图,它有以下几个属性:
queryset:指定查询集。这里我们用自定义管理器获取已发布的博文。如果不写queryset,直接写model = Post,Django 会默认用Post.objects.all()查询所有博文。context_object_name:指定传给模板的变量名为posts。如果不设置这个属性,默认的变量名是object_list。paginate_by:设置分页,每页显示 3 条数据。template_name:指定使用的模板文件。如果不设置,ListView默认会去找blog/post_list.html这个模板。
现在,编辑 blog/urls.py 路由文件,注释掉之前的 post_list 路由,换成 PostListView 类视图,如下所示:(注释第6行,添加第7行)
from django.urls import path
from . import views
app_name = 'blog' # 命名空间
urlpatterns = [
# post views
# path('', views.post_list, name='post_list'), # 博文列表路由
path('', views.PostListView.as_view(), name='post_list2'), # 博文列表路由(类视图)
path('<int:id>/', views.post_detail, name='post_detail'), # 博文详情路由
path(
'<int:year>/<int:month>/<int:day>/<slug:post>/',
views.post_detail,
name='post_detail',
),
]为了让分页功能正常工作,我们需要调整模板中分页组件使用的变量。Django 的 ListView 会把当前页对象存在 page_obj 这个变量里,所以我们要修改 post/list.html 模板,把分页导航的参数改成 page_obj,如下所示:(18行)
{% extends "blog/base.html" %}
{% block title %}程序员的小屋{% endblock %}
{% block content %}
<h1>程序员的小屋</h1>
{% for post in posts %}
<h2>
<a href="{{ post.get_absolute_url }}">
{{ post.title }}
</a>
</h2>
<p class="date">
发布时间: {{ post.publish }} 作者:{{ post.author }}
</p>
{{ post.body|truncatewords:30|linebreaks }}
{% endfor %}
{% include "pagination.html" with page=page_obj %}
{% endblock %}在浏览器中打开 http://127.0.0.1:8000/blog/,验证分页功能是否正常。效果应该和之前用 post_list 函数视图时一样。
冰封压缩机与代码提纯
Code Compactor (FBV to CBV Evolution)
Function-Based View
def post_list(req):
posts = Post.published.all()
paginator = Paginator(posts, 3)
page = req.GET.get('page')
try: # 异常处理
posts = paginator.page(page)
except PageNotAnInteger:
posts = paginator.page(1)
except EmptyPage:
posts = paginator.page(num)
return render(...)
Class-Based View
class PostListView(ListView):
queryset = Post.published.all()
context_object_name = 'posts'
paginate_by = 3
template_name = 'list.html'
几十行充满了 `try-except` 或各类判断的面条函数代码,其实背后的意图非常简单。通过对象继承,巨大的逻辑压缩机将其提提纯为一块只声明核心属性的纯净能量方块(继承至 ListView)。
Dozens of lines of spaghetti code filled with pagination and error handling logic can be compacted. By inheriting from generic Class-Based Views like ListView, it is stripped down to just configuring a few pure properties.
四、创建评论系统
接下来我们继续扩展博客应用,给它加上评论功能,让用户可以对博文发表评论。评论系统需要以下几个部分:
一个 Comment 模型,用来存储用户对博文的评论(上面已完成)
一个 Django 表单,让用户提交评论并自动做数据验证
一个视图函数,处理表单提交并把新评论保存到数据库
前端模板中的评论列表和评论表单,嵌入到博文详情页中
- blog应用中完整的 models.py 模型:
# 导入Django的admin模块
from django.contrib import admin
# 导入博客应用中的Comment和Post模型
from .models import Comment, Post
# 注册Post模型到Admin站点(装饰器写法)
@admin.register(Post)
class PostAdmin(admin.ModelAdmin):
# 在Admin中显示的字段
list_display = ['title', 'slug', 'author', 'publish', 'status']
list_filter = ['status', 'created', 'publish', 'author'] # 过滤选项(侧边栏)
search_fields = ['title', 'body'] # 搜索字段
prepopulated_fields = {'slug': ('title',)} # slug字段自动填充
raw_id_fields = ['author']
date_hierarchy = 'publish' # 日期分层导航
ordering = ['status', 'publish'] # 默认排序
show_facets = admin.ShowFacets.ALWAYS # 始终显示侧边栏过滤器
# 注册Comment模型到Admin站点(装饰器写法)
@admin.register(Comment)
class CommentAdmin(admin.ModelAdmin):
# 在Admin中显示的字段
list_display = ['name', 'email', 'post', 'created', 'active']
list_filter = ['active', 'created', 'updated'] # 过滤选项(侧边栏)
search_fields = ['name', 'email', 'body'] # 搜索字段
# 可选:自定义 Admin 站点标题
admin.site.site_header = '博客管理系统' # 登录页面和后台顶部标题
admin.site.site_title = '博客管理后台' # 浏览器标签页标题
admin.site.index_title = '欢迎使用博客管理系统' # 首页标题- 完整的 blog/admin.py 文件代码:
# 导入Django的admin模块
from django.contrib import admin
# 导入博客应用中的Comment和Post模型
from .models import Comment, Post
# 注册Post模型到Admin站点(装饰器写法)
@admin.register(Post)
class PostAdmin(admin.ModelAdmin):
# 在Admin中显示的字段
list_display = ['title', 'slug', 'author', 'publish', 'status']
list_filter = ['status', 'created', 'publish', 'author'] # 过滤选项(侧边栏)
search_fields = ['title', 'body'] # 搜索字段
prepopulated_fields = {'slug': ('title',)} # slug字段自动填充
raw_id_fields = ['author']
date_hierarchy = 'publish' # 日期分层导航
ordering = ['status', 'publish'] # 默认排序
show_facets = admin.ShowFacets.ALWAYS # 始终显示侧边栏过滤器
# 注册Comment模型到Admin站点(装饰器写法)
@admin.register(Comment)
class CommentAdmin(admin.ModelAdmin):
# 在Admin中显示的字段
list_display = ['name', 'email', 'post', 'created', 'active']
list_filter = ['active', 'created', 'updated'] # 过滤选项(侧边栏)
search_fields = ['name', 'email', 'body'] # 搜索字段
# 可选:自定义 Admin 站点标题
admin.site.site_header = '博客管理系统' # 登录页面和后台顶部标题
admin.site.site_title = '博客管理后台' # 浏览器标签页标题
admin.site.index_title = '欢迎使用博客管理系统' # 首页标题- 创建 blog/forms.py 表单模板文件,并添加代码
from django import forms # 导入Django的表单模块
from .models import Comment # 导入Comment模型
# 定义Comment表单类,基于ModelForm
class CommentForm(forms.ModelForm):
# 元数据类,指定关联的模型和字段
class Meta:
model = Comment # 关联的模型是Comment
fields = ['name', 'email', 'body'] # 包含的字段- 完整 blog/views.py 视图文件
# Paginator: 用于分页显示查询结果
# PageNotAnInteger: 处理页码不是整数的异常
# EmptyPage: 处理页码超出范围的异常
from django.core.paginator import EmptyPage, PageNotAnInteger, Paginator
# get_object_or_404: 如果查询对象不存在,自动返回404页面,简化异常处理
# render: 将模板和上下文数据渲染为HTTP响应,是常用的视图函数
from django.shortcuts import get_object_or_404, render
from django.views.decorators.http import require_POST
# ListView: Django通用视图类,用于显示对象列表
from django.views.generic import ListView
# 导入自定义的表单类
from .forms import CommentForm
from .models import Post # 导入Post模型
# 博客文章列表视图,支持分页
def post_list(request):
post_list = Post.published.all() # 获取所有已发布文章
paginator = Paginator(post_list, 3) # 每页显示3篇文章
page_number = request.GET.get('page', 1) # 获取当前页码,默认第一页
try:
# 获取当前页的文章列表,如果页码无效会抛出异常
posts = paginator.page(page_number)
except PageNotAnInteger:
# 处理页码不是整数的情况,返回第一页
posts = paginator.page(1)
except EmptyPage:
# 处理页码超出范围的情况,返回最后一页
posts = paginator.page(paginator.num_pages)
return render(
request, # 请求对象,模板中可以使用请求上下文
'blog/post/list.html', # 模板路径(从templates目录开始)
{'posts': posts} # 上下文数据,将posts传递给模板
)
# 博客文章详情视图,显示单篇文章及其评论
# def post_detail(request, year, month, day, post):
def post_detail(request, id):
# 使用get_object_or_404函数简化查询和异常处理
post = get_object_or_404(
Post, # 要查询的模型类
status=Post.Status.PUBLISHED, # 只查询已发布的文章
id=id, # 根据传入的id参数进行查询
# slug=post,
# publish__year=year,
# publish__month=month,
# publish__day=day,
)
# 获取博文的活跃评论列表信息
comments = post.comments.filter(active=True)
# 生成用户评论表单
form = CommentForm()
return render(
request,
'blog/post/detail.html',
{
'post': post,
'comments': comments,
'form': form
},
)
# 备选博客文章列表视图类,使用Django通用视图ListView
class PostListView(ListView):
queryset = Post.published.all()
context_object_name = 'posts'
paginate_by = 3
template_name = 'blog/post/list.html'
# 处理博客文章评论提交的视图函数
@require_POST
def post_comment(request, post_id):
# 获取对应的文章对象,确保文章已发布
post = get_object_or_404(
Post,
id=post_id,
status=Post.Status.PUBLISHED
)
comment = None
# 创建CommentForm实例,绑定POST数据
form = CommentForm(data=request.POST)
if form.is_valid():
# 创建评论对象而不将其保存到数据库
comment = form.save(commit=False)
comment.post = post # 将博文分配给评论
comment.save() # 将评论保存到数据库
# 渲染评论结果页面
return render(
request,
'blog/post/comment.html',
{
'post': post,
'form': form,
'comment': comment
},
)海关安检与盖章查扣
Customs Inspection (ModelForm `commit=False` Workflow)
Comment Data
客户端 POST
is_valid()
commit=False
comment.save()
form = CommentForm(data=req.POST)
if form.is_valid():
comment = form.save(commit=False)
comment.post = current_post # 手动盖章补全关联
comment.save() # 真正入库放行
有时表单缺失了必要的归属外键信息,不能直接存库。commit=False 就像是将包裹在安检后“拿在手上”,在代码里手动为其盖上归属印章后,最后再真正放行入库 save()。
Sometimes a form lacks a required foreign key. `commit=False` acts like holding a validated package at customs: you manually stamp it with the missing relationship in code, and then finally let it pass to the database.
- 完整的 blog/urls.py 路由文件
from django.urls import path
from . import views
app_name = 'blog'
urlpatterns = [
# Post views
# path('', views.post_list, name='post_list'), # 博文列表路由
path('', views.PostListView.as_view(), name='post_list'), # 博文列表路由
path('<int:id>/', views.post_detail, name='post_detail'), # 博文详情路由
path(
'<int:year>/<int:month>/<int:day>/<slug:post>/',
views.post_detail,
name='post_detail',
),
path(
'<int:post_id>/comment/', views.post_comment, name='post_comment'
),
]- 前端模板文件结构
blog 应用目录
├── templates # 默认博客模版目录
│ ├── pagination.html # 通用模板分页导航模板
│ └── blog
│ ├── base.html # 公共博文父模版文件
│ └── post
│ ├── includes
│ │ └─ comment_form.html # 博文评论表单文件
│ ├─ comment.html # 博文评论添加成功提示文件
│ ├─ list.html # 博文列表模版文件
│ └─ detail.html # 博文详情模版文件- comment.html 文件代码:
{% extends "blog/base.html" %}
{% block title %}添加一条评论{% endblock %}
{% block content %}
{% if comment %}
<h2>您的评论已添加成功。</h2> <br/>
<p><a href="{{ post.get_absolute_url }}">返回博文</a></p>
{% else %}
{% include "blog/post/includes/comment_form.html" %}
{% endif %}
{% endblock %}- comment_form.html 文件代码:
<h2>添加新评论</h2>
<form action="{% url "blog:post_comment" post.id %}" method="post">
<div class="left">
{{ form.name.as_field_group }}
</div>
<div class="left">
{{ form.email.as_field_group }}
</div>
{{ form.body.as_field_group }}
{% csrf_token %}
<p><input type="submit" value="确认提交"></p>
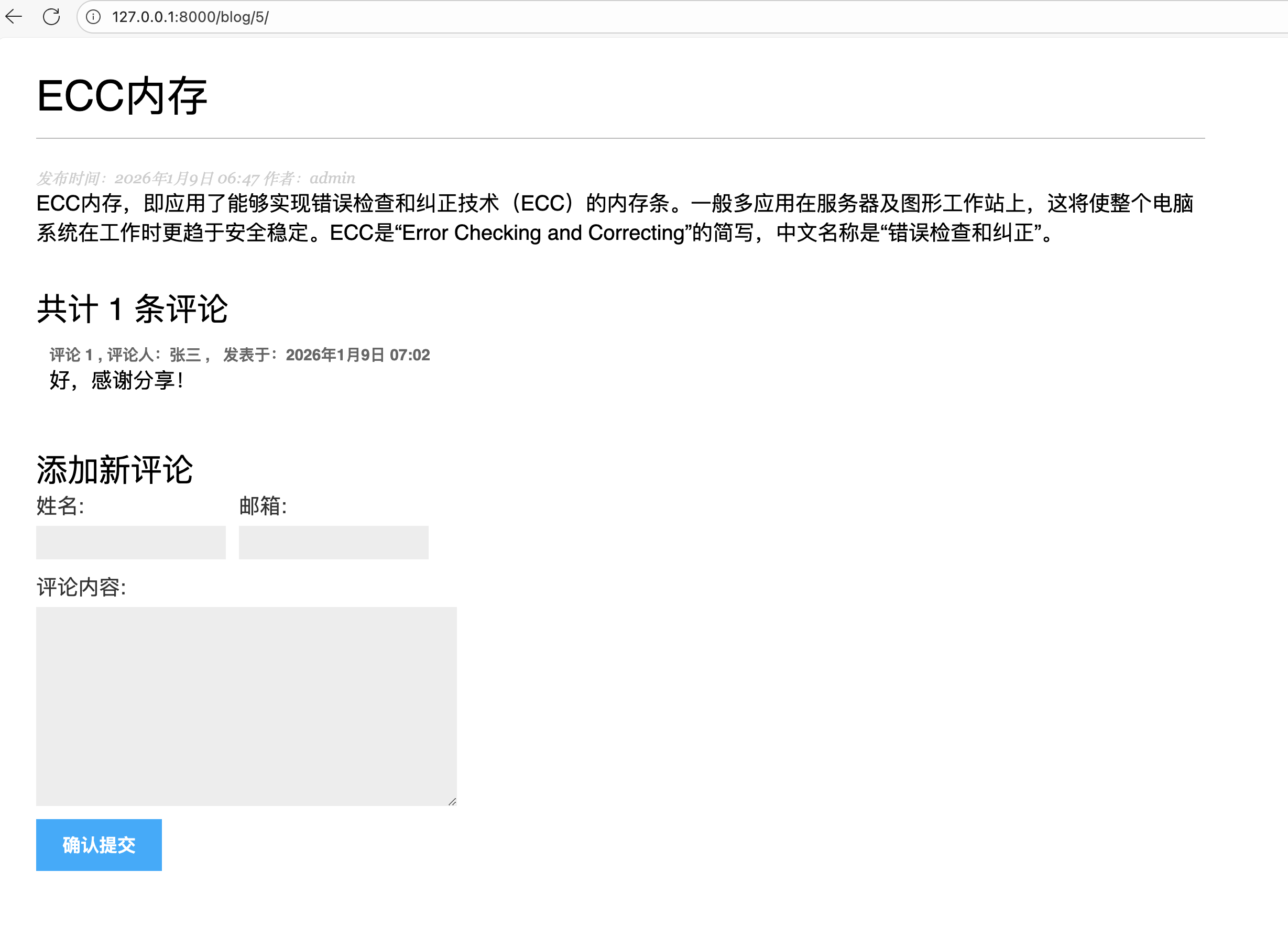
</form>- 编辑:detail.html 博文详情模板文件:
{% extends "blog/base.html" %}
{% block title %}{{ post.title }}{% endblock %}
{% block content %}
<h1>{{ post.title }}</h1>
<p class="date">
发布时间:{{ post.publish }} 作者:{{ post.author }}
</p>
{{ post.body|linebreaks }}
{% with comments.count as total_comments %}
<h2>
共计 {{ total_comments }} 条评论
</h2>
{% endwith %}
{% for comment in comments %}
<div class="comment">
<p class="info">
评论 {{ forloop.counter }} , 评论人:{{ comment.name }} ,  
发表于:{{ comment.created }}
</p>
{{ comment.body|linebreaks }}
</div>
{% empty %}
<p>目前这里暂无评论。</p>
{% endfor %}
{% include "blog/post/includes/comment_form.html" %}
{% endblock %}最终完整代码:mysite.zip
7. 预览效果: